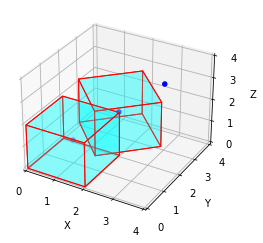
This function determines if points are within a set of rotated 3D boxes and returns a boolean array indicating the results.
Type
Details
points
ndarray
Float array [N, *]
boxes
ndarray
Float array [M, 7] or [M, 9], with first 6 dimensions x, y, z, length, width, height, last dimension yaw angle
Exported source
def points_in_rbbox(points: np.ndarray, # Float array [N, *] boxes: np.ndarray # Float array [M, 7] or [M, 9], with first 6 dimensions x, y, z, length, width, height, last dimension yaw angle ): # Bool array of shape [N, M]"""This function determines if points are within a set of rotated 3D boxes and returns a boolean array indicating the results.""" indices = np.zeros((points.shape[0], boxes.shape[0]), dtype=bool) # Bool array of shape [N, M] points_in_boxes_jit(points, boxes, indices)return indices
# Test Datapoints = np.array([ [1.0, 1.0, 1.0], [2.0, 2.0, 2.0], [3.0, 3.0, 3.0]])boxes = np.array([ [1.0, 1.0, 1.0, 2.0, 2.0, 2.0, 0.0], # Box centered at (1,1,1) with length=2, width=2, height=2, no rotation [2.0, 2.0, 2.0, 2.0, 2.0, 2.0, np.pi/4] # Box centered at (2,2,2) with length=2, width=2, height=2, rotated 45 degrees])# Expected output: array of shape (3, 2)# For each point, we check if it is within each of the two boxesindices = points_in_rbbox(points, boxes)print("Points:\n", points)print("\nBoxes:\n", boxes)print("\nIndices (Points in Boxes):\n", indices)
The BaseDataset class is designed to serve as a base class for different types of datasets. It provides methods and properties for loading, processing, and evaluating data, making it easier to handle different datasets in a consistent manner.
Type
Default
Details
root_path
Root path of the dataset
info_path
Path to the info file
sampler
NoneType
None
Sampler for sampling data
loading_pipelines
NoneType
None
Loading pipelines
augmentation
NoneType
None
Augmentation pipelines
prepare_label
NoneType
None
Prepare label pipelines
evaluations
NoneType
None
Evaluation pipelines
create_database
bool
False
Whether to create database
use_gt_sampling
bool
True
Whether to use ground truth sampling
Exported source
class BaseDataset(Dataset):""" The `BaseDataset` class is designed to serve as a base class for different types of datasets. It provides methods and properties for loading, processing, and evaluating data, making it easier to handle different datasets in a consistent manner. """def__init__(self, root_path, # Root path of the dataset info_path, # Path to the info file sampler=None, # Sampler for sampling data loading_pipelines=None, # Loading pipelines augmentation=None, # Augmentation pipelines prepare_label=None, # Prepare label pipelines evaluations=None, # Evaluation pipelines create_database=False, # Whether to create database use_gt_sampling=True# Whether to use ground truth sampling ):self._info_path = info_pathself._root_path = Path(root_path)self.loading_pipelines = loading_pipelinesself.augmentations = augmentationself.prepare_label = prepare_labelself.evaluations = evaluationsself.create_database = create_databaseself.use_gt_sampling = use_gt_samplingself.load_infos()if use_gt_sampling and sampler isnotNone:self.sampler = sampler()else:self.sampler =Nonedef__len__(self):returnlen(self.infos)def load_infos(self):withopen(os.path.join(self._root_path, self._info_path), "rb") as f:self.infos = pickle.load(f)def evaluation(self):"""Dataset must provide a evaluation function to evaluate model."""# support different evaluation tasksraiseNotImplementedErrordef load_pointcloud(self, res, info):raiseNotImplementedErrordef load_box3d(self, res, info): res["annotations"] = {'gt_boxes': info["gt_boxes"].astype(np.float32).copy(),'gt_names': np.array(info["gt_names"]).reshape(-1).copy(), }return resdef__getitem__(self, idx): info =self.infos[idx] res = {"token": info["token"]}ifself.loading_pipelines isnotNone:for lp inself.loading_pipelines: res =getattr(self, lp)(res, info)ifself.sampler isnotNone: sampled_dict =self.sampler.sample_all( res['annotations']['gt_boxes'], res["annotations"]['gt_names'] )if sampled_dict isnotNone: sampled_gt_names = sampled_dict["gt_names"] sampled_gt_boxes = sampled_dict["gt_boxes"] sampled_points = sampled_dict["points"] sampled_gt_masks = sampled_dict["gt_masks"] res['annotations']["gt_names"] = np.concatenate( [res['annotations']["gt_names"], sampled_gt_names], axis=0 ) res['annotations']["gt_boxes"] = np.concatenate( [res['annotations']["gt_boxes"], sampled_gt_boxes] )# remove points in sampled gt boxes sampled_point_indices = points_in_rbbox( res['points'], sampled_gt_boxes[sampled_gt_masks]) res['points'] = res['points'][np.logical_not( sampled_point_indices.any(-1))] res['points'] = np.concatenate( [sampled_points, res['points']], axis=0)ifself.augmentations isnotNone:for aug inself.augmentations.values(): res = aug(res)ifself.prepare_label isnotNone:for _, pl inself.prepare_label.items(): res = pl(res)if'annotations'in res and (notself.create_database):del res['annotations']return resdef format_eval(self):raiseNotImplementedError
The eval_main function is designed to evaluate the NuScenes dataset using a specified evaluation configuration. It follows these steps:
Configuration Setup: The function starts by creating a configuration object using the config_factory function, passing in the eval_version parameter. This configuration specifies the evaluation settings to be used.
Initialization: It then initializes a NuScenesEval object, passing in the NuScenes dataset object (nusc), the evaluation configuration (cfg), the path to the results file (res_path), the dataset split to evaluate on (eval_set), and the directory to store the evaluation results (output_dir). The verbose=True parameter enables detailed logging during the evaluation process.
Evaluation: Finally, the function calls the main method of the NuScenesEval object to perform the evaluation. The plot_examples=0 parameter indicates that no example plots should be generated during the evaluation.
By organizing the evaluation process into a function, eval_main simplifies the process of setting up and running evaluations on the NuScenes dataset, ensuring that the correct configuration and parameters are used.
Evaluate the detection results on the nuScenes dataset.
Details
nusc
NuScenes dataset object.
eval_version
Version of the evaluation configuration to use.
res_path
Path to the results file.
eval_set
The dataset split to evaluate on (e.g., ‘val’, ‘test’).
output_dir
Directory to store the evaluation results.
Exported source
def eval_main(nusc, # NuScenes dataset object. eval_version, # Version of the evaluation configuration to use. res_path, # Path to the results file. eval_set, # The dataset split to evaluate on (e.g., 'val', 'test'). output_dir # Directory to store the evaluation results. ):""" Evaluate the detection results on the nuScenes dataset. """ cfg = config_factory(eval_version) nusc_eval = NuScenesEval( nusc, config=cfg, result_path=res_path, eval_set=eval_set, output_dir=output_dir, verbose=True, ) _ = nusc_eval.main(plot_examples=0,)
The NuScenesDataset class is designed to handle the NuScenes dataset. This class inherits from the BaseDataset class and includes methods to load, process, and evaluate data from the NuScenes dataset.
Type
Default
Details
info_path
Path to dataset information file
root_path
Path to root directory of dataset
nsweeps
Number of sweeps (LiDAR frames) to use
sampler
NoneType
None
Sampler for dataset
loading_pipelines
NoneType
None
Loading pipelines for data processing
augmentation
NoneType
None
Data augmentation methods
prepare_label
NoneType
None
Method for preparing labels
class_names
list
[]
List of class names
resampling
bool
False
Whether to resample dataset
evaluations
NoneType
None
Evaluation methods
create_database
bool
False
Whether to create a database
use_gt_sampling
bool
True
Whether to use ground truth sampling
version
str
v1.0-trainval
Dataset version
Exported source
class NuScenesDataset(BaseDataset): # NuScenes dataset class""" The `NuScenesDataset` class is designed to handle the NuScenes dataset. This class inherits from the `BaseDataset` class and includes methods to load, process, and evaluate data from the NuScenes dataset. """def__init__(self, info_path, # Path to dataset information file root_path, # Path to root directory of dataset nsweeps, # Number of sweeps (LiDAR frames) to use sampler=None, # Sampler for dataset loading_pipelines=None, # Loading pipelines for data processing augmentation=None, # Data augmentation methods prepare_label=None, # Method for preparing labels class_names=[], # List of class names resampling=False, # Whether to resample dataset evaluations=None, # Evaluation methods create_database=False, # Whether to create a database use_gt_sampling=True, # Whether to use ground truth sampling version="v1.0-trainval"# Dataset version ): # NuScenes datasetsuper(NuScenesDataset, self).__init__( root_path, info_path, sampler, loading_pipelines, augmentation, prepare_label, evaluations, create_database, use_gt_sampling=use_gt_sampling) # Initialize base classself.nsweeps = nsweepsassertself.nsweeps >0, "At least input one sweep please!"# Ensure at least one sweep is usedself._class_names =list(itertools.chain(*[t for t in class_names])) # Flatten class names listself.version = versionif resampling:self.cbgs() # Resample dataset if neededdef cbgs(self): # Performs class-balanced resampling on the dataset by oversampling underrepresented classes _cls_infos = {name: [] for name inself._class_names} # Initialize dictionary for class infofor info inself.infos: # Iterate over dataset informationfor name inset(info["gt_names"]): # For each unique ground truth nameif name inself._class_names: _cls_infos[name].append(info) # Add info to corresponding class duplicated_samples =sum([len(v) for _, v in _cls_infos.items()]) # Total number of samples after duplication _cls_dist = {k: len(v) / duplicated_samples for k, v in _cls_infos.items()} # Distribution of classes _nusc_infos = [] frac =1.0/len(self._class_names) # Fraction for resampling ratios = [frac / v for v in _cls_dist.values()] # Calculate resampling ratiosfor cls_infos, ratio inzip(list(_cls_infos.values()), ratios): _nusc_infos += np.random.choice(cls_infos, int(len(cls_infos) * ratio)).tolist() # Resample and add to infosself.infos = _nusc_infos # Update dataset informationdef read_file(self, path, num_point_feature=4): # Reads a point cloud file and returns the points in the specified format points = np.fromfile(os.path.join(self._root_path, path), dtype=np.float32).reshape(-1, 5)[:, :num_point_feature] # Read point cloud file and reshapereturn points # Return points of shape (N, num_point_feature)def read_sweep(self, sweep, min_distance=1.0): # Reads a sweep file, applies transformations, removes points too close to the origin, and returns the points and their timestamps points_sweep =self.read_file(str(sweep["lidar_path"])).T # Read sweep file and transpose, shape (num_point_feature, N) nbr_points = points_sweep.shape[1]if sweep["transform_matrix"] isnotNone: points_sweep[:3, :] = sweep["transform_matrix"].dot( np.vstack((points_sweep[:3, :], np.ones(nbr_points))))[:3, :] # Apply transformation matrix points_sweep =self.remove_close(points_sweep, min_distance) # Remove points too close to the origin curr_times = sweep["time_lag"] * np.ones((1, points_sweep.shape[1])) # Create current times arrayreturn points_sweep.T, curr_times.T # Return points and times of shape (N, num_point_feature), (N, 1)@staticmethoddef remove_close(points, radius: float): # Removes points that are too close to the origin""" Removes point too close within a certain radius from origin. :param radius: Radius below which points are removed. """ x_filt = np.abs(points[0, :]) < radius y_filt = np.abs(points[1, :]) < radius not_close = np.logical_not(np.logical_and(x_filt, y_filt)) # Create filter for points outside the radius points = points[:, not_close] # Apply filter to pointsreturn points # Return filtered pointsdef load_pointcloud(self, res, info): # Loads a point cloud and its sweeps, concatenating them together with their timestamps lidar_path = info["lidar_path"] points =self.read_file(str(lidar_path)) # Read point cloud file sweep_points_list = [points] # Initialize sweep points list sweep_times_list = [np.zeros((points.shape[0], 1))] # Initialize sweep times listfor i inrange(len(info["sweeps"])): # Iterate over sweeps sweep = info["sweeps"][i] points_sweep, times_sweep =self.read_sweep(sweep) # Read each sweep sweep_points_list.append(points_sweep) # Add sweep points to list sweep_times_list.append(times_sweep) # Add sweep times to list points = np.concatenate(sweep_points_list, axis=0) # Concatenate all points times = np.concatenate(sweep_times_list, axis=0).astype(points.dtype) # Concatenate all times res["points"] = np.hstack([points, times]) # Combine points and timesreturn res # Return updated resultdef evaluation(self, detections, output_dir=None, testset=False): # Evaluates detections against the dataset, calculates metrics, and optionally performs resampling. It returns the results or None if the evaluation is not performed version =self.version eval_set_map = {"v1.0-mini": "mini_val","v1.0-trainval": "val","v1.0-test": "test", } dets = [v for _, v in detections.items()] # Get list of detections nusc_annos = {"results": {},"meta": None, } nusc = NuScenes(version=version, dataroot=str(self._root_path), verbose=True) # Initialize NuScenes dataset mapped_class_names = []for n inself._class_names: mapped_class_names.append(n) # Map class namesfor det in dets: # Iterate over detections annos = [] boxes = _second_det_to_nusc_box(det) # Convert detection to NuScenes box format boxes = _lidar_nusc_box_to_global(nusc, boxes, det["token"]) # Convert lidar boxes to global coordinatesfor i, box inenumerate(boxes): name = mapped_class_names[box.label]if np.sqrt(box.velocity[0] **2+ box.velocity[1] **2) >0.2:if name in ["car","construction_vehicle","bus","truck","trailer", ]: attr ="vehicle.moving"elif name in ["bicycle", "motorcycle"]: attr ="cycle.with_rider"else: attr =Noneelse:if name in ["pedestrian"]: attr ="pedestrian.standing"elif name in ["bus"]: attr ="vehicle.parked"else: attr =None nusc_anno = {"sample_token": det["token"],"translation": box.center.tolist(), # Box center coordinates"size": box.wlh.tolist(), # Box size (width, length, height)"rotation": box.orientation.elements.tolist(), # Box rotation (quaternion)"velocity": box.velocity[:2].tolist(), # Box velocity (x, y)"detection_name": name, # Class name"detection_score": box.score, # Detection score"attribute_name": attrif attr isnotNoneelsemax(cls_attr_dist[name].items(), key=operator.itemgetter(1))[0], # Attribute name } annos.append(nusc_anno) nusc_annos["results"].update({det["token"]: annos}) # Add annotations to results nusc_annos["meta"] = {"use_camera": False,"use_lidar": True,"use_radar": False,"use_map": False,"use_external": False, } name =self._info_path.split("/")[-1].split(".")[0] res_path =str(Path(output_dir) / Path(name +".json"))withopen(res_path, "w") as f: json.dump(nusc_annos, f) # Save annotations to JSON fileprint(f"Finish generate predictions for testset, save to {res_path}")ifnot testset: eval_main( nusc,"detection_cvpr_2019", res_path, eval_set_map[self.version], output_dir, ) # Run evaluationwithopen(Path(output_dir) /"metrics_summary.json", "r") as f: metrics = json.load(f) # Load evaluation metrics detail = {} result =f"Nusc {version} Evaluation\n"for name in mapped_class_names: # Iterate over class names detail[name] = {}for k, v in metrics["label_aps"][name].items(): # Iterate over evaluation metrics detail[name][f"dist@{k}"] = v threshs =", ".join(list(metrics["label_aps"][name].keys())) # Distance thresholds scores =list(metrics["label_aps"][name].values()) # Scores mean =sum(scores) /len(scores) # Mean score scores =", ".join([f"{s *100:.2f}"for s in scores]) # Format scores result +=f"{name} Nusc dist AP@{threshs}\n" result += scores result +=f" mean AP: {mean}" result +="\n" res_nusc = {"results": {"nusc": result},"detail": {"nusc": detail}, }else: res_nusc =Noneif res_nusc isnotNone: res = {"results": {"nusc": res_nusc["results"]["nusc"], },"detail": {"eval.nusc": res_nusc["detail"]["nusc"], }, }return res['results'] # Return resultselse:returnNone# Return None if no results
The cbgs method in the NuScenesDataset class performs class-balanced resampling on the dataset. This technique is employed to address the imbalance in the number of samples for different classes within the dataset. Here is a step-by-step breakdown of how the cbgs method works:
Initialize Class Information Dictionary:
_cls_infos = {name: [] for name inself._class_names}
This creates a dictionary where the keys are the class names, and the values are empty lists. This dictionary will store the dataset information for each class.
Populate Class Information Dictionary:
for info inself.infos:for name inset(info["gt_names"]):if name inself._class_names: _cls_infos[name].append(info)
The method iterates over the dataset information (self.infos). For each dataset entry (info), it checks the ground truth names (info["gt_names"]). If a ground truth name is in the list of class names (self._class_names), it adds the corresponding info to the list for that class in _cls_infos.
Calculate Class Distributions:
duplicated_samples =sum([len(v) for _, v in _cls_infos.items()])_cls_dist = {k: len(v) / duplicated_samples for k, v in _cls_infos.items()}
The total number of samples after duplication is calculated (duplicated_samples). Then, the distribution of each class in the dataset is computed (_cls_dist), which is the number of samples for each class divided by the total number of samples.
Initialize Variables for Resampling:
_nusc_infos = []frac =1.0/len(self._class_names)ratios = [frac / v for v in _cls_dist.values()]
An empty list _nusc_infos is initialized to store the resampled dataset information. The fraction (frac) is calculated as the inverse of the number of class names. Resampling ratios are then computed for each class based on the class distribution (_cls_dist).
Perform Resampling:
for cls_infos, ratio inzip(list(_cls_infos.values()), ratios): _nusc_infos += np.random.choice(cls_infos, int(len(cls_infos) * ratio)).tolist()
For each class’s information (cls_infos) and its corresponding resampling ratio (ratio), a number of samples proportional to the ratio are randomly selected from cls_infos and added to _nusc_infos.
Update Dataset Information:
self.infos = _nusc_infos
Finally, the dataset information (self.infos) is updated with the resampled dataset information stored in _nusc_infos.
In summary, the cbgs method addresses class imbalance by oversampling underrepresented classes to create a more balanced dataset. This is achieved by calculating the distribution of each class, determining resampling ratios, and then randomly selecting samples based on these ratios. The resulting balanced dataset is then used for further processing and training.
# Test cbgs method (performs class-balanced resampling on the dataset by oversampling underrepresented classes)print("Before resampling:")for cls_name in train_dataset._class_names:print(f"{cls_name}: {sum(1for info in train_dataset.infos if cls_name in info['gt_names'])}")train_dataset.cbgs()print("\nAfter resampling:")for cls_name in train_dataset._class_names:print(f"{cls_name}: {sum(1for info in train_dataset.infos if cls_name in info['gt_names'])}")