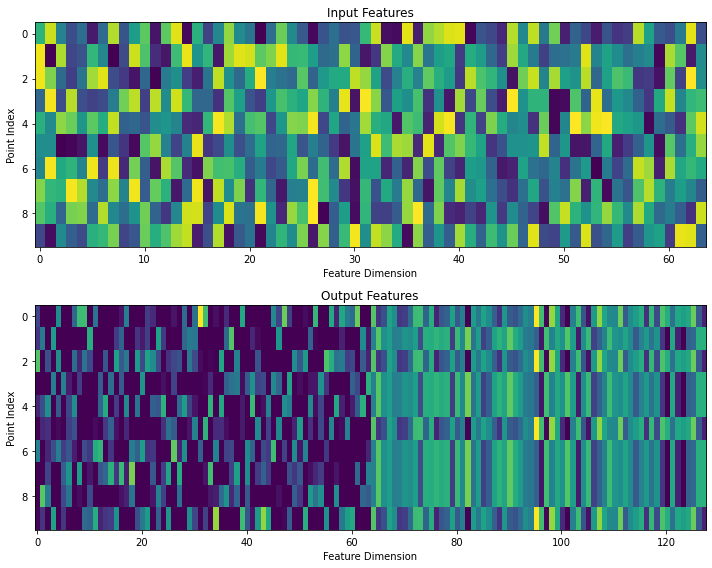
Pillar Feature Net Layer. The Pillar Feature Net could be composed of a series of these layers, but the PointPillars paper results only used a single PFNLayer. This layer performs a similar role as second.pytorch.voxelnet.VFELayer.
Type
Default
Details
in_channels
int
Number of input channels
out_channels
int
Number of output channels
norm_cfg
NoneType
None
Normalization config (not used here, but could be for future extensions)
last_layer
bool
False
If last_layer, there is no concatenation of features
Exported source
class PFNLayer(nn.Module):""" Pillar Feature Net Layer. The Pillar Feature Net could be composed of a series of these layers, but the PointPillars paper results only used a single PFNLayer. This layer performs a similar role as second.pytorch.voxelnet.VFELayer. """def__init__(self, in_channels: int, # Number of input channels out_channels: int, # Number of output channels norm_cfg=None, # Normalization config (not used here, but could be for future extensions) last_layer: bool=False# If last_layer, there is no concatenation of features ):super().__init__()self.last_vfe = last_layer # Check if this is the last layerifnotself.last_vfe: out_channels = out_channels //2# If not the last layer, half the output channelsself.units = out_channelsself.linear = nn.Linear(in_channels, out_channels, bias=False) # Linear layer to transform inputsself.norm = nn.BatchNorm1d(out_channels, eps=1e-3, momentum=0.01) # Batch normalizationdef forward(self, inputs, unq_inv): torch.backends.cudnn.enabled =False# Disable cuDNN for compatibility reasons x =self.linear(inputs) # Apply linear transformation x =self.norm(x) # Apply batch normalization x = F.relu(x) # Apply ReLU activation torch.backends.cudnn.enabled =True# Re-enable cuDNN# max pooling feat_max = torch_scatter.scatter_max(x, unq_inv, dim=0)[0] # Perform scatter max pooling x_max = feat_max[unq_inv] # Gather the max features for each pointifself.last_vfe:return x_max # If this is the last layer, return the max featureselse: x_concatenated = torch.cat([x, x_max], dim=1) # Otherwise, concatenate the original and max featuresreturn x_concatenated # Return the concatenated features
The PFNLayer Class class implements a layer of the Pillar Feature Net. It includes a linear transformation, batch normalization, and ReLU activation. It also performs scatter max pooling to extract the maximum features per pillar. The PFNLayer class essentially extracts features from point clouds.
Differences from PyTorch Standard Implementations
This class extends basic PyTorch components to perform specific operations for 3D point cloud data. The main differences include:
Scatter Operations: Instead of using standard pooling operations like max pooling, the class employs torch_scatter.scatter_max, which is crucial for handling sparse point cloud data. PyTorch does not natively support this type of scatter operation.
Custom Feature Concatenation: The concatenation of original and max-pooled features, dependent on whether the layer is the last in the network, is a custom behavior not found in standard PyTorch layers.
Abstractions Provided by PFNLayer
Pooling in Point Clouds: PFNLayer abstracts the complexity of performing scatter-based max pooling, which is not straightforward in PyTorch’s standard API.
Conditional Feature Concatenation: It abstracts the logic of deciding whether or not to concatenate features based on whether it’s the last layer.
Custom Batch Normalization: The use of nn.BatchNorm1d with a custom eps and momentum is abstracted, so the user doesn’t need to handle these details directly.
Limitations Compared to a Direct PyTorch Implementation
Limited Flexibility: The class is specialized for the PointPillars architecture. A more direct PyTorch implementation might allow for greater flexibility in terms of pooling strategies, feature transformations, and layer configurations.
Hardcoded Operations: The specific operations (like the choice of ReLU activation, BatchNorm1d, and scatter_max) are hardcoded. A more direct PyTorch approach would allow these choices to be more easily customized or replaced with alternatives.
*PillarNet. The network performs dynamic pillar scatter that convert point cloud into pillar representation and extract pillar features
Reference: PointPillars: Fast Encoders for Object Detection from Point Clouds (https://arxiv.org/abs/1812.05784) End-to-End Multi-View Fusion for 3D Object Detection in LiDAR Point Clouds (https://arxiv.org/abs/1910.06528)*
Type
Details
num_input_features
int
Number of input features
voxel_size
list
A list that defines the size of the voxels (grids) in the x and y dimensions.
pc_range
list
A list defining the range of the point cloud data in the x and y dimensions. This is used to filter and normalize the point cloud data. Only utilize x and y min
Exported source
class PillarNet(nn.Module):""" PillarNet. The network performs dynamic pillar scatter that convert point cloud into pillar representation and extract pillar features Reference: PointPillars: Fast Encoders for Object Detection from Point Clouds (https://arxiv.org/abs/1812.05784) End-to-End Multi-View Fusion for 3D Object Detection in LiDAR Point Clouds (https://arxiv.org/abs/1910.06528) """def__init__(self, num_input_features: int, # Number of input features voxel_size: list, # A list that defines the size of the voxels (grids) in the x and y dimensions. pc_range: list, # A list defining the range of the point cloud data in the x and y dimensions. This is used to filter and normalize the point cloud data. Only utilize x and y min ):super().__init__()self.voxel_size = np.array(voxel_size)self.pc_range = np.array(pc_range)def forward(self, points: torch.Tensor # Points in LiDAR coordinate, shape: (N, d), format: batch_id, x, y, z, feat1, ... ): device = points.device dtype = points.dtype# discard out of range points grid_size = (self.pc_range[3:] -self.pc_range[:3] )/self.voxel_size # x, y, z grid_size = np.round(grid_size, 0, grid_size).astype(np.int64) voxel_size = torch.from_numpy(self.voxel_size).type_as(points).to(device) pc_range = torch.from_numpy(self.pc_range).type_as(points).to(device) points_coords = ( points[:, 1:4] - pc_range[:3].view(-1, 3)) / voxel_size.view(-1, 3) # x, y, z mask =reduce(torch.logical_and, (points_coords[:, 0] >=0, points_coords[:, 0] < grid_size[0], points_coords[:, 1] >=0, points_coords[:, 1] < grid_size[1])) points = points[mask] points_coords = points_coords[mask] points_coords = points_coords.long() batch_idx = points[:, 0:1].long() points_index = torch.cat((batch_idx, points_coords[:, :2]), dim=1) unq, unq_inv = torch.unique(points_index, return_inverse=True, dim=0) unq = unq.int() points_mean_scatter = torch_scatter.scatter_mean( points[:, 1:4], unq_inv, dim=0) f_cluster = points[:, 1:4] - points_mean_scatter[unq_inv]# Find distance of x, y, and z from pillar center f_center = points[:, 1:3] - (points_coords[:, :2].to(dtype) * voxel_size[:2].unsqueeze(0) + voxel_size[:2].unsqueeze(0) /2+ pc_range[:2].unsqueeze(0))# Combine together feature decorations features = torch.cat([points[:, 1:], f_cluster, f_center], dim=-1)return features, unq[:, [0, 2, 1]], unq_inv, grid_size[[1, 0]]
Point Filtering: The input points are filtered based on the specified pc_range to discard points that are outside the defined range.
Grid Size Calculation: The grid size is computed based on the voxel_size and pc_range, which determines the resolution of the voxelization.
Point Coordinates Normalization: The point coordinates are normalized with respect to the voxel size and point cloud range, converting the continuous coordinates into discrete voxel indices.
Point Clustering: The points are clustered into pillars based on their voxel indices.
Feature Decoration: Additional features are calculated, including:
f_cluster: The distance of each point from the mean of its cluster (pillar).
f_center: The distance of each point from the center of its respective voxel.
Feature Aggregation: The original point features, along with the newly computed features (f_cluster and f_center), are concatenated to form the final feature set for each point.
Return Values: The method returns the final point features, the unique pillar indices, the inverse indices used for aggregation, and the grid size.
Differences
Abstraction of Point Cloud Operations:
The PillarNet class abstracts the voxelization and feature extraction process, which would otherwise require manual implementation using basic PyTorch operations. It provides a higher-level interface to work with point cloud data, simplifying the process of converting point clouds into pillar-based representations.
Integration of Advanced Operations:
Operations like torch_scatter.scatter_mean are used for efficiently computing cluster mean features. These operations are not directly available in standard PyTorch and require the use of external libraries like torch_scatter.
Grid Management:
The class handles the computation of grid size and point normalization internally, which would otherwise require manual calculation and management in a more direct implementation.
Limitations
Flexibility:
While PillarNet provides a streamlined approach to pillar feature extraction, it may lack the flexibility needed for more customized operations or for handling point cloud data in formats that differ from the assumptions made in the class.
Limited Customization:
The class is designed for a specific type of pillar-based representation. Users who require different types of voxelization or feature extraction strategies may find it limiting and may need to modify or extend the class, which could be more cumbersome than implementing a direct approach from scratch.
# Create a sample point cloud with shape (N, d)# Here, d includes batch_id, x, y, z, and some additional features (e.g., intensity)points = torch.tensor([ [0, 1.0, 2.0, 3.0, 0.5], [0, 2.5, 3.5, 4.5, 0.6], [1, 5.0, 6.0, 7.0, 0.7], [1, 8.0, 9.0, 10.0, 0.8]], dtype=torch.float32)# Define the number of input features (excluding batch_id, x, y, z)num_input_features = points.shape[1] -1# Define voxel size (x_size, y_size, z_size)voxel_size = [0.5, 0.5, 0.5]# Define point cloud range (x_min, y_min, z_min, x_max, y_max, z_max)pc_range = [0, 0, 0, 10, 10, 10]# Create an instance of PillarNetpillar_net = PillarNet(num_input_features, voxel_size, pc_range)# Forward pass with the sample pointsfeatures, unique_voxel_indices, inverse_indices, grid_size = pillar_net(points)# Print the resultsprint("Features:", features)print("Unique Voxel Indices:", unique_voxel_indices)print("Inverse Indices:", inverse_indices)print("Grid Size:", grid_size)
Pillar Feature Net. The network prepares the pillar features and performs forward pass through PFNLayers. This net performs a similar role to SECOND’s second.pytorch.voxelnet.VoxelFeatureExtractor.
Type
Details
num_input_features
int
Number of input features
num_filters
list
Number of features in each of the N PFNLayers
voxel_size
list
Size of voxels, only utilize x and y size
pc_range
list
Point cloud range, only utilize x and y min
norm_cfg
None
Normalization config
Exported source
class PillarFeatureNet(nn.Module):""" Pillar Feature Net. The network prepares the pillar features and performs forward pass through PFNLayers. This net performs a similar role to SECOND's second.pytorch.voxelnet.VoxelFeatureExtractor. """def__init__(self, num_input_features: int, # Number of input features num_filters: list, # Number of features in each of the N PFNLayers voxel_size: list, # Size of voxels, only utilize x and y size pc_range: list, # Point cloud range, only utilize x and y min norm_cfg:None, # Normalization config ):super().__init__()assertlen(num_filters) >0 num_input_features +=5# Create PillarFeatureNet layers num_filters = [num_input_features] +list(num_filters) pfn_layers = []for i inrange(len(num_filters) -1): in_filters = num_filters[i] out_filters = num_filters[i +1]if i <len(num_filters) -2: last_layer =Falseelse: last_layer =True pfn_layers.append( PFNLayer( in_filters, out_filters, norm_cfg=norm_cfg, last_layer=last_layer ) )self.pfn_layers = nn.ModuleList(pfn_layers)self.feature_output_dim = num_filters[-1]self.voxel_size = np.array(voxel_size)self.pc_range = np.array(pc_range)self.voxelization = PillarNet(num_input_features, voxel_size, pc_range)def forward(self, points): features, coords, unq_inv, grid_size =self.voxelization(points)# Forward pass through PFNLayersfor pfn inself.pfn_layers: features = pfn(features, unq_inv) # num_points, dim_feat feat_max = torch_scatter.scatter_max(features, unq_inv, dim=0)[0]return feat_max, coords, grid_size
The PillarFeatureNet class is designed for preparing pillar features from the point cloud data, used in 3D object detection tasks in LiDAR-based perception systems. This network handles the transformation of raw point cloud data into a more structured and feature-rich representation, which will be essential for further processing in the object detection.
Funcionality
Initialization (__init__ method):
Input Features Augmentation: The class initializes by augmenting the input features with additional spatial information, increasing the dimensionality by 5 (which might include features like the relative position of points within a pillar, etc.).
Layer Creation: It then creates a sequence of layers, PFNLayers, which perform the feature extraction. The number of layers and their configuration are determined by the num_filters parameter.
Voxelization: The class initializes the voxelization process, converting the raw point cloud data into a voxel grid with specified voxel_size and within a specified pc_range (point cloud range). This voxelization is essential for handling irregular point clouds by grouping points into a regular grid structure, called “pillars.”
Forward Pass (forward method):
Voxelization: The input point cloud is first voxelized, where the points are grouped into pillars, and features are extracted.
PFN Layers: The extracted features are passed through the PFNLayers, where each layer performs a certain amount of processing. These layers typically involve operations like PointNet-style feature learning.
Max Pooling: Finally, the features are aggregated using a max-pooling operation (torch_scatter.scatter_max), which pools the features across the points in each pillar to get a fixed-size feature vector for each pillar.
Abstraction
This class abstracts several operations that would require more manual implementation in pure PyTorch. For instance, voxelization and the subsequent grouping of points into pillars are handled internally by the PillarNet class.
The abstraction can reduce flexibility. If you need to tweak certain aspects of the feature extraction or voxelization process, this might be harder to do compared to a more manual approach where every operation is explicit.
# Define input parameters for PillarFeatureNet# Mock values for demonstration purposesnum_input_features =3num_filters = [64, 128]voxel_size = [0.2, 0.2, 0.2]pc_range = [0, 0, 0, 50, 50, 50]norm_cfg =None# Instantiate the PillarFeatureNetpillar_feature_net = PillarFeatureNet( num_input_features=num_input_features, num_filters=num_filters, voxel_size=voxel_size, pc_range=pc_range, norm_cfg=norm_cfg)# Create some dummy input points# Each point might have x, y, z, intensity, etc.num_points =100# Number of points in the point cloudpoints = torch.rand(num_points, num_input_features +1) # Random points (x, y, z, intensity)# Run a forward passfeat_max, coords, grid_size = pillar_feature_net(points)# Print the outputsprint("Max Features:\n", feat_max)print("Voxel Coordinates:\n", coords)print("Grid Size:\n", grid_size)
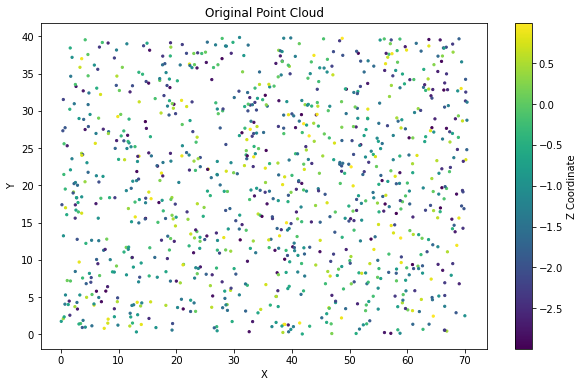
# Create some dummy input pointsnum_points =100# Number of points in the point cloudpoints = torch.rand(num_points, num_input_features +1) # Random points (x, y, z, intensity)# Visualize the input using matplotlibfig = plt.figure()ax = fig.add_subplot(111, projection='3d')# Plot point cloud coordinatesax.scatter(points[:, 0].numpy(), points[:, 1].numpy(), points[:, 2].numpy(), c='r', marker='o')# Label axesax.set_xlabel('X')ax.set_ylabel('Y')ax.set_zlabel('Z')# Titleax.set_title('Point Cloud Coordinates')plt.show()
class DynamicVoxelEncoder(nn.Module):""" Dynamic version of VoxelFeatureExtractorV3 """def__init__(self):super(DynamicVoxelEncoder, self).__init__()def forward(self, inputs, unq_inv): features = torch_scatter.scatter_mean(inputs, unq_inv, dim=0)return features
The DynamicVoxelEncoder class is a module that serves as a custom feature extractor for voxel-based data, utilizing dynamic computations to process input features.
The method performs a scatter operation using the torch_scatter.scatter_mean function, which computes the mean of features that belong to the same group, as indicated by the unq_inv tensor. The result is a tensor of aggregated features, where each feature corresponds to a unique group.
This design makes the DynamicVoxelEncoder easy to integrate into larger architectures that require voxel-based feature extraction, such as 3D object detection networks.
This class performs dynamic voxelization on input point clouds. It converts point coordinates into voxel grid coordinates and removes points that fall outside the specified range.*
Details
voxel_size
The size of each voxel in the grid. It is expected to be a 3-element list or array that defines the size of the voxel in the x, y, and z dimensions.
pc_range
The range of the point cloud. It’s a 6-element list or array that specifies the minimum and maximum bounds in the x, y, and z dimensions.
Exported source
class VoxelNet(nn.Module):""" Dynamic voxelization for point clouds This class performs dynamic voxelization on input point clouds. It converts point coordinates into voxel grid coordinates and removes points that fall outside the specified range. """def__init__(self, voxel_size, # The size of each voxel in the grid. It is expected to be a 3-element list or array that defines the size of the voxel in the x, y, and z dimensions. pc_range # The range of the point cloud. It's a 6-element list or array that specifies the minimum and maximum bounds in the x, y, and z dimensions. ):super().__init__()self.voxel_size = np.array(voxel_size)self.pc_range = np.array(pc_range)def forward(self, points):""" points: Tensor: (N, d), batch_id, x, y, z, ... """ device = points.device# voxel range of x, y, z grid_size = (self.pc_range[3:] -self.pc_range[:3]) /self.voxel_size grid_size = np.round(grid_size, 0, grid_size).astype(np.int64) voxel_size = torch.from_numpy(self.voxel_size).type_as(points).to(device) pc_range = torch.from_numpy(self.pc_range).type_as(points).to(device) points_coords = ( points[:, 1:4] - pc_range[:3].view(-1, 3)) / voxel_size.view(-1, 3) # x, y, z mask =reduce(torch.logical_and, (points_coords[:, 0] >=0, points_coords[:, 0] < grid_size[0], points_coords[:, 1] >=0, points_coords[:, 1] < grid_size[1], points_coords[:, 2] >=0, points_coords[:, 2] < grid_size[2])) # remove the points out of range points = points[mask] points_coords = points_coords[mask] points_coords = points_coords.long() batch_idx = points[:, 0:1].long() point_index = torch.cat((batch_idx, points_coords), dim=1) unq, unq_inv = torch.unique(point_index, return_inverse=True, dim=0) unq = unq.int() features = points[:, 1:]return features, unq[:, [0, 3, 2, 1]], unq_inv, grid_size[[2, 1, 0]]
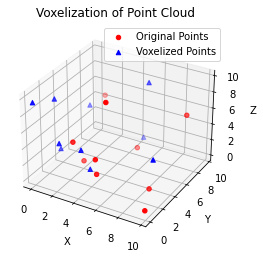
The VoxelNet class is designed for performing dynamic voxelization on 3D point clouds. Voxelization is a process where a 3D space is divided into a grid of equally sized cubes (voxels), and points from the point cloud are assigned to these voxels based on their spatial coordinates.
Here’s a breakdown of the core functionality of the VoxelNet class:
Forward Method:
The forward method takes as input a tensor of points. This tensor has the shape (N, d) where N is the number of points and d is the number of features per point. The first feature is the batch_id, and the next three are the coordinates x, y, z. Additional features can be present as well.
The method calculates the size of the voxel grid (grid_size) by dividing the range of the point cloud by the voxel size.
It then computes the voxel grid coordinates (points_coords) for each point by subtracting the minimum point cloud range and dividing by the voxel size.
Points that fall outside the specified range (outside the grid) are filtered out using a mask.
The remaining points and their corresponding voxel coordinates are then converted to integer indices.
The method creates a unique index (point_index) for each point using its batch_id and voxel grid coordinates.
It finds unique voxel indices and returns the following:
features: The features of the points that remain after filtering.
unq: The unique voxel indices corresponding to the unique points.
unq_inv: The inverse of the unique voxel indices, mapping back to the original point indices.
grid_size: The size of the voxel grid.
# Create an instance of VoxelNetvoxel_size = [0.5, 0.5, 0.5]pc_range = [0, 0, 0, 10, 10, 10]voxel_net = VoxelNet(voxel_size, pc_range)# Generate synthetic point cloud databatch_size =1num_points =10points = torch.cat(( torch.zeros(num_points, 1), # batch_id torch.rand(num_points, 3) *10# x, y, z), dim=1)# Forward passfeatures, voxel_coords, unq_inv, grid_size = voxel_net(points)# Print input and outputprint("Input Points:")print(points)print("\nFeatures:")print(features)print("\nVoxel Coordinates:")print(voxel_coords)print("\nUnique Inverse Indices:")print(unq_inv)print("\nGrid Size:")print(grid_size)# Visual demonstration using matplotlib# Plot original and voxelized pointsfig = plt.figure()ax = fig.add_subplot(111, projection='3d')ax.scatter(points[:, 1], points[:, 2], points[:, 3], c='r', marker='o', label='Original Points')# Convert voxel coordinates to real world coordinatesvoxel_size = np.array([0.5, 0.5, 0.5])pc_range_min = np.array([0, 0, 0])real_coords = voxel_coords[:, 1:4].numpy() * voxel_size + pc_range_minax.scatter(real_coords[:, 0], real_coords[:, 1], real_coords[:, 2], c='b', marker='^', label='Voxelized Points')ax.set_xlabel('X')ax.set_ylabel('Y')ax.set_zlabel('Z')plt.legend()plt.title('Voxelization of Point Cloud')plt.show()
This class performs dynamic voxelization of point clouds and then encodes the voxel features using DynamicVoxelEncoder.
Details
voxel_size
size of voxel
pc_range
point cloud range
Exported source
class VoxelFeatureNet(nn.Module):""" This class performs dynamic voxelization of point clouds and then encodes the voxel features using DynamicVoxelEncoder. """def__init__(self, voxel_size, # size of voxel pc_range # point cloud range ):super().__init__()self.voxelization = VoxelNet(voxel_size, pc_range)self.voxel_encoder = DynamicVoxelEncoder()def forward(self, points): features, coords, unq_inv, grid_size =self.voxelization(points) features =self.voxel_encoder(features, unq_inv)return features, coords, grid_size
The VoxelFeatureNet class is designed to perform dynamic voxelization and then encode the voxelized features. It integrates the functionality of the VoxelNet and DynamicVoxelEncoder classes to provide a streamlined process for transforming raw point cloud data into meaningful features that can be used in further processing, such as in neural networks for tasks like object detection, segmentation, or 3D scene understanding.
VoxelNet is responsible for dynamically voxelizing the input point clouds.
It first takes raw point cloud data (points), which includes the batch index and the coordinates (x, y, z), along with other associated features.
The point cloud data is mapped onto a voxel grid based on the specified voxel_size and pc_range.
Points that fall outside the specified range are filtered out.
The voxel grid coordinates for each point are calculated and stored, and duplicate voxel indices are merged, with unique voxel indices being identified (unq), and a mapping from points to voxels is maintained (unq_inv).
DynamicVoxelEncoder Integration:
Once the voxelization process is completed, the DynamicVoxelEncoder takes over.
This encoder aggregates the features of all points that fall into the same voxel by computing the mean of the features (scatter_mean function).
This step effectively reduces the point cloud data into a more compact voxel-based representation, where each voxel holds the average feature of all points within it.
Return Values:
The class returns the aggregated voxel features, the voxel coordinates (coords), and the grid size (grid_size), which can be used for further processing in downstream tasks.
Overall, VoxelFeatureNet provides a structured way to convert raw point cloud data into voxelized features.
# Create an instance of VoxelFeatureNetvoxel_size = [0.1, 0.1, 0.1]pc_range = [0, -40, -3, 70.4, 40, 1]voxel_feature_net = VoxelFeatureNet(voxel_size, pc_range)# Generate synthetic point cloud data# Format: [batch_id, x, y, z, ...]batch_size =2num_points =500num_features =4# x, y, z, intensitypoints = torch.cat([ torch.randint(0, batch_size, (num_points, 1)).float(), # batch_id torch.rand(num_points, 3) * torch.tensor([70.4, 80, 4]) - torch.tensor([0, 40, 3]), # x, y, z torch.rand(num_points, num_features -3) # additional features], dim=1)# Forward pass through the VoxelFeatureNetfeatures, coords, grid_size = voxel_feature_net(points)
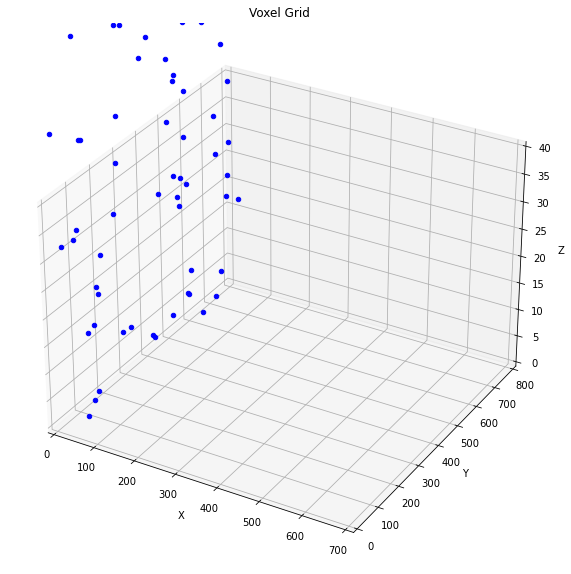
# Visual demonstration using matplotlibdef plot_voxel_grid(coords, grid_size): fig = plt.figure(figsize=(10, 10)) ax = fig.add_subplot(111, projection='3d')# Plot the voxel grid ax.set_xlim(0, grid_size[2]) ax.set_ylim(0, grid_size[1]) ax.set_zlim(0, grid_size[0]) ax.set_xlabel('X') ax.set_ylabel('Y') ax.set_zlabel('Z')# Plot the occupied voxelsfor coord in coords: ax.scatter(coord[1], coord[2], coord[3], c='b', marker='o') plt.title('Voxel Grid') plt.show()# Plot the voxel grid with occupied coordinatesplot_voxel_grid(coords, grid_size)
class PointNet(nn.Module):""" Linear Process for point feature """def__init__(self, in_channels:int, # Number of input channels out_channels:int# Number of output channels ):super().__init__()self.linear = nn.Linear(in_channels, out_channels, bias=False)self.norm = nn.BatchNorm1d(out_channels, eps=1e-3, momentum=0.01)def forward(self, points): torch.backends.cudnn.enabled =False x =self.linear(points) x =self.norm(x) x = F.relu(x) torch.backends.cudnn.enabled =Truereturn x
The PointNet class is a simple neural network module designed for processing point features. This class abstracts a linear transformation followed by normalization and activation.
Linear Transformation: It transforms the input features (point features) using a linear layer, effectively mapping the input dimension (in_channels) to the desired output dimension (out_channels).
Normalization: After the linear transformation, the features are normalized using Batch Normalization to ensure stable and faster training by maintaining consistent feature distributions.
Activation: The normalized features are passed through a ReLU activation function, introducing non-linearity and enabling the network to model complex relationships between input features.
Fixed Architecture:
The class is hardcoded to a single linear layer followed by batch normalization and ReLU activation. This limits its flexibility if more complex architectures or other types of layers (e.g., convolutional layers, more sophisticated non-linearities) are needed. Also it isn’t possible to change the number of layers or the activation function, nor the epsilon and momentum values for batch normalization, since they are hardcoded.
This class implements the voxelization process, converting point clouds into voxel grid indices and computing features for each point relative to the voxel grid.
Details
voxel_size
Size of of each voxel in the grid, only utilize x and y size.
pc_range
Point cloud range. Only utilize x and y min.
Exported source
class PillarVoxelNet(nn.Module):""" This class implements the voxelization process, converting point clouds into voxel grid indices and computing features for each point relative to the voxel grid. """def__init__(self, voxel_size, # Size of of each voxel in the grid, only utilize x and y size. pc_range # Point cloud range. Only utilize x and y min. ):super().__init__()self.voxel_size = np.array(voxel_size)self.pc_range = np.array(pc_range)def forward(self, points): device = points.device dtype = points.dtype grid_size = (self.pc_range[3:] -self.pc_range[:3] )/self.voxel_size # x, y, z grid_size = np.round(grid_size, 0, grid_size).astype(np.int64) voxel_size = torch.from_numpy(self.voxel_size).type_as(points).to(device) pc_range = torch.from_numpy(self.pc_range).type_as(points).to(device) points_coords = ( points[:, 1:4] - pc_range[:3].view(-1, 3)) / voxel_size.view(-1, 3) # x, y, z points_coords[:, 0] = torch.clamp( points_coords[:, 0], 0, grid_size[0] -1) points_coords[:, 1] = torch.clamp( points_coords[:, 1], 0, grid_size[1] -1) points_coords[:, 2] = torch.clamp( points_coords[:, 2], 0, grid_size[2] -1) points_coords = points_coords.long() batch_idx = points[:, 0:1].long() points_index = torch.cat((batch_idx, points_coords[:, :2]), dim=1) unq, unq_inv = torch.unique(points_index, return_inverse=True, dim=0) unq = unq.int() # breakpoint() points_mean_scatter = torch_scatter.scatter_mean( points[:, 1:4], unq_inv, dim=0) f_cluster = points[:, 1:4] - points_mean_scatter[unq_inv]# Find distance of x, y, and z from pillar center f_center = points[:, 1:3] - (points_coords[:, :2].to(dtype) * voxel_size[:2].unsqueeze(0) + voxel_size[:2].unsqueeze(0) /2+ pc_range[:2].unsqueeze(0))# Combine together feature decorations features = torch.cat([points[:, 1:], f_cluster, f_center], dim=-1)return features, unq[:, [0, 2, 1]], unq_inv, grid_size[[1, 0]]
The PillarVoxelNet class is a component in the process of converting raw LiDAR point cloud data into a structured grid format for 3D object detection tasks. It is designed to convert unstructured LiDAR point cloud data into a structured voxel grid. By transforming the raw point data into a format that can be processed by the subsequent network layers, the class enables the network to capture spatial relationships.
Components of the Class:
Forward Pass (forward Method):
The forward method takes in a batch of point cloud data and performs the following steps:
Grid Size Calculation: The grid size (number of voxels along each axis) is calculated by dividing the range of the point cloud by the voxel size. This defines how many voxels fit into the defined point cloud range.
Voxelization: Each point in the point cloud is converted to a coordinate within the voxel grid. This is done by normalizing the point coordinates by the voxel size and adjusting them relative to the grid.
The coordinates are then clamped to ensure they lie within the bounds of the grid.
Unique Voxel Identification: The points are then assigned to unique voxels based on their calculated voxel coordinates. The torch.unique function is used to identify unique voxel indices and the corresponding inverse indices.
Feature Computation:
Point-to-Pillar Mean: The mean position of points within each voxel (or pillar) is calculated.
Cluster Features (f_cluster): These features represent the offset of each point from the mean position of its corresponding voxel.
Centering Features (f_center): These features represent the distance of each point from the center of the voxel grid.
Finally, the original point features, cluster features, and centering features are concatenated to form the final set of features for each point.
Return Values: The method returns:
features: The enhanced point features incorporating spatial relationships.
unq: The unique voxel indices.
unq_inv: Inverse indices for reconstructing the original point set.
grid_size: The size of the voxel grid in the x and y dimensions.
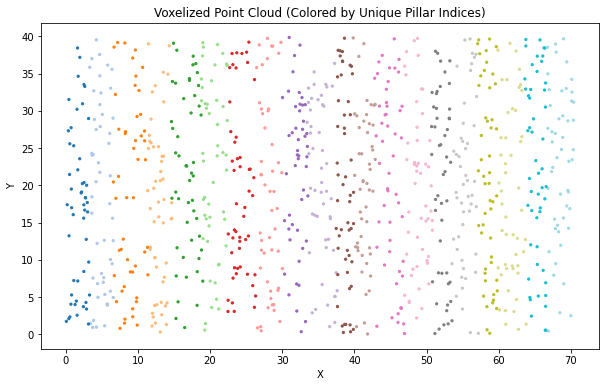
# Create an instance of PillarVoxelNetvoxel_size = [0.2, 0.2, 4]pc_range = [0, 0, -3, 70.4, 40, 1]pillar_voxel_net = PillarVoxelNet(voxel_size, pc_range)# Generate synthetic point cloud databatch_size =1num_points =10points = torch.rand(num_points, 4)points[:, 0] =0# All points belong to the same batchpoints[:, 1] = points[:, 1] * (pc_range[3] - pc_range[0]) + pc_range[0]points[:, 2] = points[:, 2] * (pc_range[4] - pc_range[1]) + pc_range[1]points[:, 3] = points[:, 3] * (pc_range[5] - pc_range[2]) + pc_range[2]# Forward passfeatures, unq, unq_inv, grid_size = pillar_voxel_net(points)# Print the resultsprint("Features:")print(features)print("\nUnique Pillar Indices (Batch, X, Y):")print(unq)print("\nGrid Size (Y, X):")print(grid_size)
Modules can also contain other Modules, allowing to nest them in a tree structure. You can assign the submodules as regular attributes::
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
Submodules assigned in this way will be registered, and will have their parameters converted too when you call :meth:to, etc.
.. note:: As per the example above, an __init__() call to the parent class must be made before assignment on the child.
ivar training: Boolean represents whether this module is in training or evaluation mode. :vartype training: bool*
Details
voxel_size
Size of each voxel, only utilize x and y size
pc_range
Point cloud range, only utilize x and y min
Exported source
class CylinderNet(nn.Module):def__init__(self, voxel_size, # Size of each voxel, only utilize x and y size pc_range # Point cloud range, only utilize x and y min ):super().__init__()self.voxel_size = np.array(voxel_size)self.pc_range = np.array(pc_range)def forward(self, points): device = points.device dtype = points.dtype points_x = points[:, 1:2] points_y = points[:, 2:3] points_z = points[:, 3:4] points_phi = torch.atan2(points_y, points_x) / np.pi *180 points_rho = torch.sqrt(points_x **2+ points_y **2) points_cylinder = torch.cat( (points[:, 0:1], points_phi, points_z, points_rho, points[:, 4:]), dim=-1) grid_size = (self.pc_range[3:] -self.pc_range[:3] )/self.voxel_size # phi, z, rho grid_size = np.round(grid_size, 0, grid_size).astype(np.int64) voxel_size = torch.from_numpy(self.voxel_size).type_as(points).to(device) pc_range = torch.from_numpy(self.pc_range).type_as(points).to(device) points_coords = ( points_cylinder[:, 1:4] - pc_range[:3].view(-1, 3)) / voxel_size.view(-1, 3) points_coords[:, 0] = torch.clamp( points_coords[:, 0], 0, grid_size[0] -1) points_coords[:, 1] = torch.clamp( points_coords[:, 1], 0, grid_size[1] -1) points_coords[:, 2] = torch.clamp( points_coords[:, 2], 0, grid_size[2] -1) points_coords = points_coords.long() batch_idx = points_cylinder[:, 0:1].long() points_index = torch.cat((batch_idx, points_coords[:, :2]), dim=1) unq, unq_inv = torch.unique(points_index, return_inverse=True, dim=0) unq = unq.int() points_mean_scatter = torch_scatter.scatter_mean( points_cylinder[:, 1:4], unq_inv, dim=0) f_cluster = points_cylinder[:, 1:4] - points_mean_scatter[unq_inv]# Find distance of x, y, and z from pillar center f_center = points_cylinder[:, 1:3] - (points_coords[:, :2].to(dtype) * voxel_size[:2].unsqueeze(0) + voxel_size[:2].unsqueeze(0) /2+ pc_range[:2].unsqueeze(0))# Combine together feature decorations features = torch.cat( [points_cylinder[:, 1:], f_cluster, f_center], dim=-1)return features, unq[:, [0, 2, 1]], unq_inv, grid_size[[1, 0]]
The CylinderNet class is a neural network module designed to transform the raw point cloud data into a cylindrical coordinate system, then organizes the points into a structured grid based on voxelization.
Functionality:
Conversion to Cylindrical Coordinates: The point cloud data initially represented in Cartesian coordinates (x, y, z) is transformed into cylindrical coordinates (φ, z, ρ), where φ is the azimuthal angle, z is the height, and ρ is the radial distance from the origin. This conversion helps align the data with the sensor’s scanning pattern, making it easier to capture relevant features.
Voxelization and Grid Size Calculation: After converting to cylindrical coordinates, the point cloud is voxelized based on the specified voxel_size. The grid_size is computed by dividing the range of the point cloud by the voxel size, resulting in the number of voxels along each axis.
Point Indexing and Unique Coordinates: The transformed points are then mapped to voxel coordinates. Each point is assigned to a voxel based on its cylindrical coordinates. The code identifies unique voxel indices and computes scatter-based statistics, such as the mean, for each voxel, which are crucial for creating features.
Feature Decoration: Additional features are computed for each point, including the difference from the voxel center and the cluster center. These features help the network learn more about the local geometry of the point cloud.
Output:
features: A tensor containing the decorated features for each point, combining the cylindrical coordinates with additional features like cluster and center distances.
unq: The unique voxel indices.
unq_inv: The inverse mapping from unique indices to the original points, used to reconstruct the point-to-voxel relationship.
grid_size: The size of the voxel grid, reordered to match the required format.
authoured by Beijing-jinyu convolution for single view
Type
Default
Details
in_channels
Number of input channels
num_filters
Number of features in each of the N PFNLayers
layer_nums
Number of blocks in each layer
ds_layer_strides
Strides of each layer
ds_num_filters
Number of features in each layer
kernel_size
Kernel size of each layer
mode
Mode of the network
voxel_size
Size of voxels, only utilize x and y size
pc_range
Point cloud range, only utilize x and y min
norm_cfg
NoneType
None
Normalization config
act_cfg
NoneType
None
Activation config
Exported source
class SingleView(nn.Module):""" authoured by Beijing-jinyu convolution for single view """def__init__(self, in_channels, # Number of input channels num_filters, # Number of features in each of the N PFNLayers layer_nums, # Number of blocks in each layer ds_layer_strides, # Strides of each layer ds_num_filters, # Number of features in each layer kernel_size, # Kernel size of each layer mode, # Mode of the network voxel_size, # Size of voxels, only utilize x and y size pc_range, # Point cloud range, only utilize x and y min norm_cfg=None, # Normalization config act_cfg=None, # Activation config ):super().__init__()self.mode = modeself.voxel_size = np.array(voxel_size[:2])self.bias = np.array(pc_range[:2]) num_filters = [in_channels] +list(num_filters) pfn_layers = []for i inrange(len(num_filters) -1): in_filters = num_filters[i] out_filters = num_filters[i +1]if i <len(num_filters) -2: last_layer =Falseelse: last_layer =True pfn_layers.append( PFNLayer( in_filters, out_filters, norm_cfg=norm_cfg, last_layer=last_layer ) ) in_filters = [num_filters[-1], *ds_num_filters[:-1]]self.pfn_layers = nn.ModuleList(pfn_layers) blocks = []for i, layer_num inenumerate(layer_nums): block =self._make_layer( in_filters[i], ds_num_filters[i], kernel_size[i], ds_layer_strides[i], layer_num) blocks.append(block)self.blocks = nn.ModuleList(blocks)self.ds_rate = np.prod(np.array(ds_layer_strides))def _make_layer(self, inplanes, planes, kernel_size, stride, num_blocks): layers = [] layers.append(SparseConvBlock(inplanes, planes, kernel_size=kernel_size, stride=stride, use_subm=False))for j inrange(num_blocks): layers.append(SparseBasicBlock(planes, kernel_size=kernel_size))return spconv.pytorch.SparseSequential(*layers)def forward(self, features, unq, unq_inv, grid_size): feature_pos = features[:,0:2] ifself.mode =='pillar'else features[:, 10:12] device = feature_pos.device voxel_size = torch.from_numpy(self.voxel_size).type_as(feature_pos).to(device) bias = torch.from_numpy(self.bias).type_as(feature_pos).to(device) feature_pos = (feature_pos - bias) / voxel_sizefor pfn inself.pfn_layers: features = pfn(features, unq_inv) # num_points, dim_feat features_voxel = torch_scatter.scatter_max(features, unq_inv, dim=0)[0] batch_size =len(torch.unique(unq[:, 0])) x = spconv.pytorch.SparseConvTensor( features_voxel, unq, grid_size, batch_size)for i inrange(len(self.blocks)): x =self.blocks[i](x) x = x.dense() feature_pos = torch.cat( (unq[unq_inv][:, 0:1], feature_pos /self.ds_rate), dim=-1)returnself.bilinear_interpolate(x, feature_pos)def bilinear_interpolate(self, image, coords):""" image: (B, C, H, W) coords: (N, 3): (B, y, x) """ x = coords[:, 1] x0 = torch.floor(x).long() x1 = x0 +1 y = coords[:, 2] y0 = torch.floor(y).long() y1 = y0 +1 B = coords[:, 0].long() x0 = torch.clamp(x0, 0, image.shape[3] -1) x1 = torch.clamp(x1, 0, image.shape[3] -1) y0 = torch.clamp(y0, 0, image.shape[2] -1) y1 = torch.clamp(y1, 0, image.shape[2] -1) Ia = image[B, :, y0, x0] Ib = image[B, :, y1, x0] Ic = image[B, :, y0, x1] Id = image[B, :, y1, x1] wa = ((x1.type(torch.float32)-x) * (y1.type(torch.float32)-y)).unsqueeze(-1) wb = ((x1.type(torch.float32)-x) * (y-y0.type(torch.float32))).unsqueeze(-1) wc = ((x-x0.type(torch.float32)) * (y1.type(torch.float32)-y)).unsqueeze(-1) wd = ((x-x0.type(torch.float32)) * (y-y0.type(torch.float32))).unsqueeze(-1) features = Ia * wa + Ib * wb + Ic * wc + Id * wdreturn features
The SingleView class is designed to perform convolutions on single views of LiDAR data. This class processes the input data through a series of convolutional layers.
Main Methods
_make_layer(): This method constructs a sequence of convolutional blocks (using sparse convolutions) for a particular layer, depending on the number of blocks specified.
forward(): This method defines the forward pass of the network. It processes the input features through the PFNLayers and blocks, applies voxelization, and finally performs bilinear interpolation to match the original resolution.
bilinear_interpolate(): This method performs bilinear interpolation to upscale the sparse feature maps to a dense format, using the original spatial coordinates of the features.
class MVFFeatureNet(nn.Module):""" authoured by Beijing-jinyu """def__init__(self, in_channels, # Number of input channels voxel_size, # Size of voxels, only utilize x and y size pc_range, # Point cloud range, only utilize x and y min cylinder_size, # Size of cylinders, only utilize x and y size cylinder_range, # Cylinder range, only utilize x and y min num_filters, # Number of features in each of the N PFNLayers layer_nums, # Number of blocks in each layer ds_layer_strides, # Strides of each layer ds_num_filters, # Number of features in each layer kernel_size, # Kernel size of each layer out_channels # Number of output channels ):super().__init__()self.in_channels = in_channelsself.voxel_size = voxel_sizeself.pc_range = pc_rangeself.cylinder_range = cylinder_rangeself.cylinder_size = cylinder_sizeself.voxelization = PillarVoxelNet(voxel_size, pc_range)self.cylinderlization = CylinderNet(cylinder_size, cylinder_range)self.pillarview = SingleView((in_channels +5) *2, num_filters, layer_nums, ds_layer_strides, ds_num_filters, kernel_size, 'pillar', self.voxel_size, self.pc_range)self.cylinderview = SingleView((in_channels +5) *2, num_filters, layer_nums, ds_layer_strides, ds_num_filters, kernel_size, 'cylinder', self.cylinder_size, self.cylinder_range)self.ds_rate = np.prod(np.array(ds_layer_strides))self.pointnet1 = PointNet((in_channels +5) *2, ds_num_filters[-1])self.pointnet2 = PointNet(ds_num_filters[-1] *3, out_channels)def forward(self, points): dtype = points.dtype pc_range = torch.tensor(self.pc_range, dtype=dtype) mask =reduce(torch.logical_and, (points[:, 1] >= pc_range[0], points[:, 1] < pc_range[3], points[:, 2] >= pc_range[1], points[:, 2] < pc_range[4], points[:, 3] >= pc_range[2], points[:, 3] < pc_range[5])) points = points[mask] pillar_feature, pillar_coords, pillar_inv, pillar_size =self.voxelization( points) cylinder_feature, cylinder_coords, cylinder_inv, cylinder_size =self.cylinderlization( points) points_feature = torch.cat((pillar_feature, cylinder_feature), dim=-1) pillar_view =self.pillarview( points_feature, pillar_coords, pillar_inv, pillar_size) cylinder_view =self.cylinderview( points_feature, cylinder_coords, cylinder_inv, cylinder_size) points_feature =self.pointnet1(points_feature) points_feature = torch.cat( (points_feature, pillar_view, cylinder_view), dim=-1) pillar_feature =self.pointnet2(points_feature) pillar_feature = torch_scatter.scatter_max( pillar_feature, pillar_inv, dim=0)[0] batch_size =len(torch.unique(pillar_coords[:, 0])) pillar_coords[:, 1:] = pillar_coords[:, 1:] //self.ds_rate pillar_size = pillar_size //self.ds_rate x = spconv.pytorch.SparseConvTensor( pillar_feature, pillar_coords, pillar_size, batch_size)return x.dense()
The MVFFeatureNet class aggregates multiple views of the point cloud data by combining the already presented classes, PillarVoxelNet and CylinderNet, to create a richer feature representation for 3D object detection tasks by using pillar-based and cylinder-based voxelization methods. The goal is to create a richer feature representation by leveraging the complementary strengths of these two methods:
Pillar Voxelization (PillarVoxelNet): Converts point cloud data into a pseudo-image representation by dividing the space into vertical columns (pillars). This method is efficient and captures the overall structure of the point cloud.
Cylinder Voxelization (CylinderNet): Divides the point cloud into cylindrical segments, which can better capture radial features and angular information that might be missed by pillar-based methods.
The MVFFeatureNet then processes these two types of voxelized features through separate convolutional pathways (SingleView) and integrates them using a series of PointNet modules to produce a final, unified feature representation.
Voxelization and Cylinderization: The point cloud data is first pre-processed by the PillarVoxelNet and CylinderNet, which convert the raw point cloud data into structured formats that are easier to process with convolutional layers.
SingleView Processing: Each view (pillar and cylinder) is processed independently using the SingleView class, which applies a series of convolutional layers to extract features. These features are later merged to provide a multi-view representation of the data.
PointNet: This module processes the combined features from both views. PointNet is well-suited for handling irregular point cloud data and is used here to further refine the feature representation.
Sparse Convolution Tensor: Finally, the processed features are packed into a sparse tensor format using spconv.pytorch.SparseConvTensor and returned as the output of the network.